What is Explainable AI (XAI)
Explainable artificial intelligence (XAI) refers to a set of processes and methods that allows humans to understand, comprehend and trust the results generated by machine learning algorithms.
XAI helps comprehend the ML model, its expected impact, and potential biases affecting performance level. Explainability fosters people’s trust and confidence in AI systems. It exemplifies model accuracy, transparency, and predictions generated by AI systems and constitutes a significant pillar of responsible AI.
Two approaches used in XAI to understand model behavior include:
- Global interpretation: The global approach provides a big-picture view of the model and how different features collectively produce a specific result.
- Local interpretation: The local approach to AI explainability considers each instance in the data and individual features that affect model predictions.
Why does AI Explainability Matter?
AI systems lack a definitive approach of “if/then” logic to explain specific ML model predictions. This lack of transparency can result in poor decisions, distrust, and denial to use AI applications. AI explainability promotes better governance and bridges the gap between tech and non-tech teams to understand projects in a better way. It ensures the following benefits:
- Auditability: XAI offers insights on various project failure modes, unknown vulnerabilities, and flaws to avoid similar mistakes in the future. It helps data science teams with better control of AI tools.
- Enhanced trust: AI serves high-risk domains and business-critical applications where trust in AI systems is not a choice but an obligation. XAI supports predictions generated by ML models with a strong evidence system.
- Scaled performance: Deeper insights on model behavior help optimize and fine-tune the performance of ML models.
- Compliance: Aligning with company policies, government regulations, citizen rights, and global industry standards is mandatory to businesses. Automated decision-making systems should comprehend their predictions with insights into the logic involved and possible consequences.
Operating XAI tools
Reading SHAP values
SHapley Additive exPlanations is a game-theoretic approach helping explain the output generated by any machine learning model. SHAP computes the contribution of eachep feature corresponding to a specific prediction to explain it.
SHAP helps understand the ‘why’ behind ML predictions and how your model predicts in a certain way. It brings explainability to model predictions by computing the contribution of each feature to the model prediction.
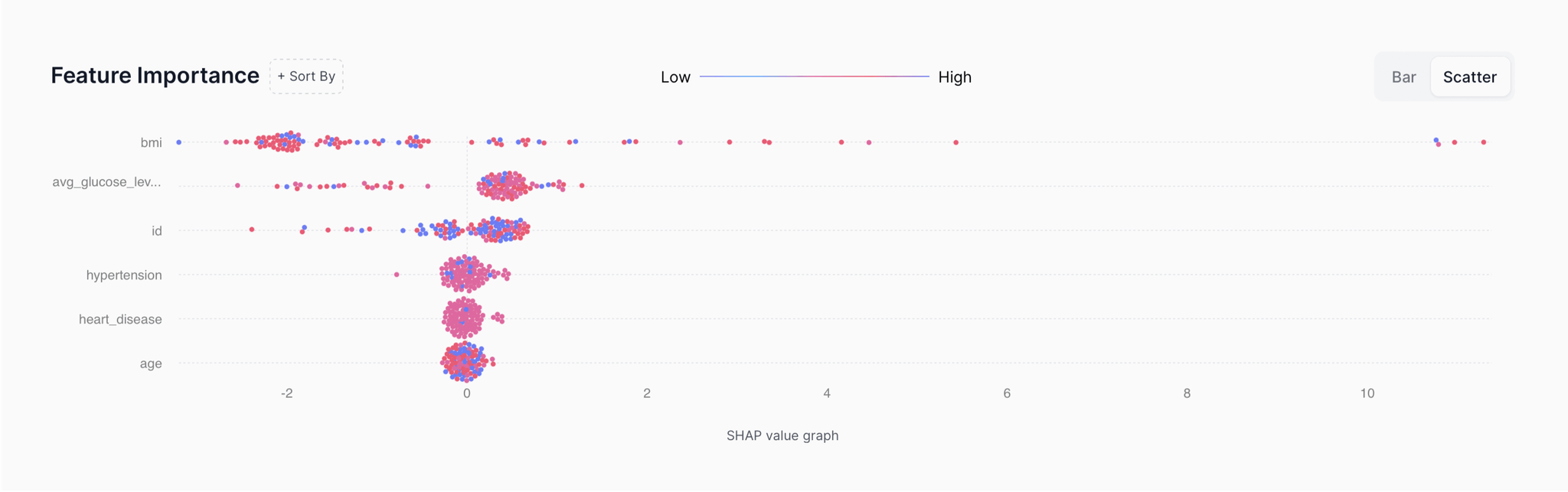
Red represents higher values of the feature while blue represents lower values. The plot (as demonstrated in the image) shows how the direction of values impacts the model either positively or negatively. Positive SHAP values represent a positive impact on model predictions (example: classified as 1) while negative SHAP values hint toward lower predictions (example: classified as 0).
Irrespective of the directionality, the average SHAP values can also be considered to understand the overall impact of the feature on the model.
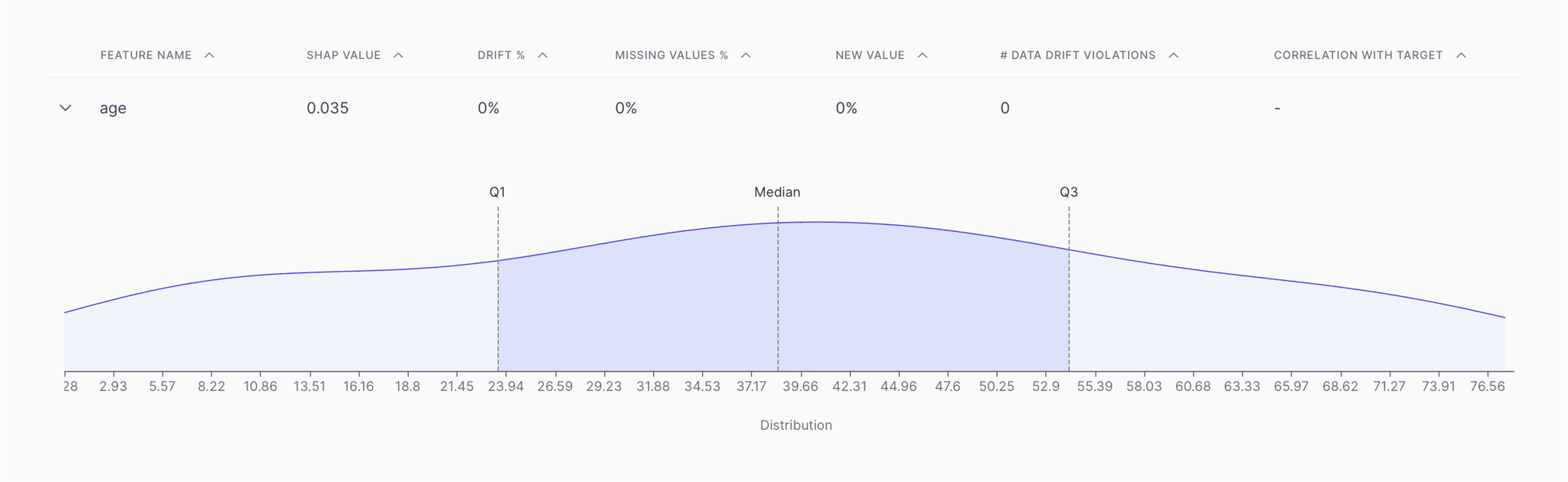
Detecting anomalies
Anomalies are harmful to models and are often the reason behind disruptions or issues. It is possible to detect subtle patterns that hint toward anomalies right at the onset of shifting behavior. XAI ensures that disruptive outliers are caught early on and the causes behind them are also uncovered.
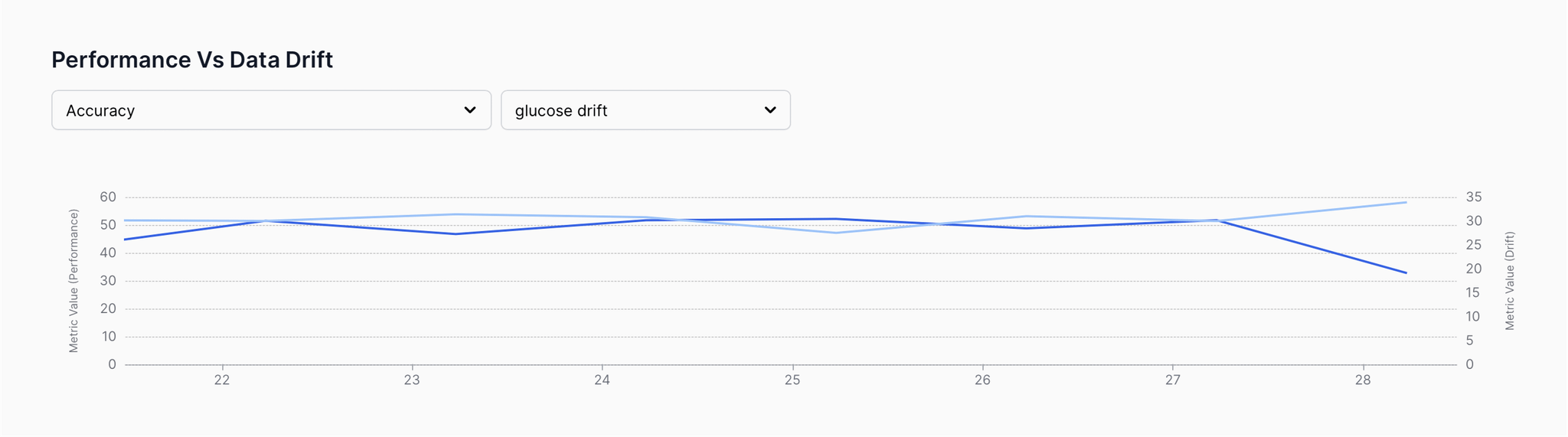
Finding causal relationships
Causal relationships are the crux of root cause analysis. By understanding the cause behind an event, it is possible to resolve the issue at the root without wasting any time scanning for the irritants.
XAI helps to understand relationships between:
- dependent and the independent variables
- features
- changing data patterns and model performance
- data quality and feature impact
- and much more.